VoiceSens
Adding Voice Biometrics to your Application.
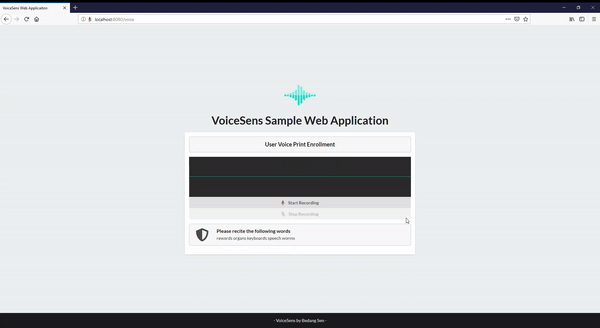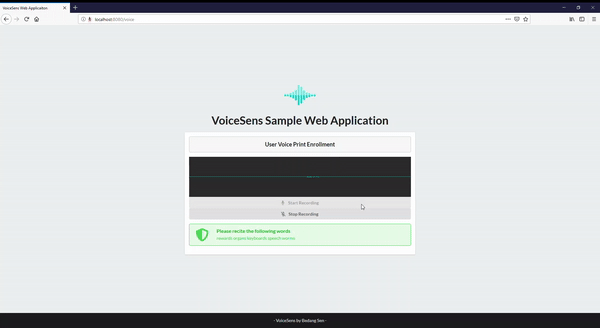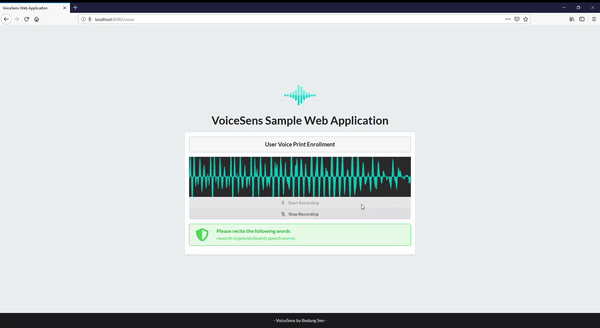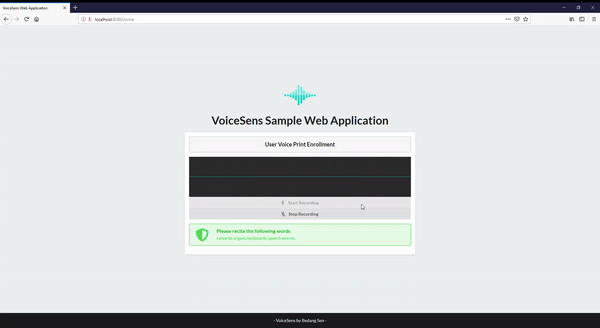
VoiceSens is a text independent voice biometric solution developed to combat some of the shortcomings of standard authentication techniques like passwords and pincodes, as well as current available voice biometric solutions. The solution is developed in Python and uses Watson Speech to Text (speech recognition).
VoiceSens Homepage
- Enroll a new user
- Authenticate an existing user.
Voice Biometrics Page . When you record your voice sample, the first thing you do is record the environmental sound. This creates a baseline for noise in the following recording, increasing the accuracy of your results. Once you are done with that you can proceed with reciting the randomly generated words. If the fuzzy matching ratio between the generated words and recognised words is less than 65, the recorded voice phrase will not be accepted, and you will be asked to record your voice sample again.